
PersonalizationのデータをDataCloud(Data360)で活用する
Data Cloud の基本と活用法!
MA課題をデータで解決する
方法とは?
本ホワイトペーパーでは、Data Cloudの基礎を知りたい企業様や、データ活用を強化しマーケティング施策の効果を最大化していきたい企業様向けに、Data Cloudの導入・運用を成功させるためのポイントをご紹介いたします。
\詳細はこちらをクリック/

本記事では、Marketing Cloud PersonalizationのデータをSalesforce Data Cloudに取り込む際の設定方法をステップバイステップで解説します。実際の設定作業から、連携されるデータの種類、そしてその活用方法まで、一連の内容をご紹介します。PersonalizationとData Cloudの連携にご興味のある方は、ぜひ最後までお読みください。
toBeマーケティング株式会社では、Data Cloudの初期導入支援・導入後の保守・伴走支援までをご提供しています。
⇒ Data Cloudサービスの詳細はこちら
また、Salesforce Marketing Cloudの導入から活用、運用までをトータルでサポートしています。One to Oneのカスタマージャーニーを実現するために、お客様の課題や目標に合わせて最適なマーケティング戦略を策定し、その実行を支援いたします。
⇒ Marketing Cloud Engagement導入支援の詳細はこちら (Personalizationも含む)
具体的には、企業が保有する複数のデータソースを整理・統合し、ID解決やデータモデリングを通じてマーケティング施策に活用できるデータ環境を整備します。
また、セグメント設計から施策連携まで一貫してサポートし、データをスムーズにマーケティング施策へ活かすための体制づくりを支援しています。
⇒ 詳細はこちらよりお気軽にお問い合わせください!
1. Personalizationとは?
Personalizationは、Webやアプリの顧客行動データをリアルタイムに収集し、AIやルールを使用して、最適化されたコンテンツを個々の顧客に合わせて提供するツールです。
2. Personalization とData Cloudを連携することで得られる効果
Personalizationで収集したWeb/アプリのデータをData Cloudに連携することで、より詳細な顧客理解を深めることができ、高度なセグメンテーションやターゲティング、データ分析といった用途にPersonalizationのデータを用いることが可能となります。
3. 設定方法
ここからは具体的な設定方法を解説していきます。
PersonalizationのデータをData Cloudに取り込む場合は、以下の①〜⑤の手順が必要となります。
①匿名データの連携可否を設定する
PersonalizationのデータをData Cloudに取り込む前に、匿名データを連携するかどうかを決定しましょう。
デフォルトの設定では、「匿名データは連携しない」となっているため、そのままで良い場合は、この手順はスキップしていただいて問題ありません。
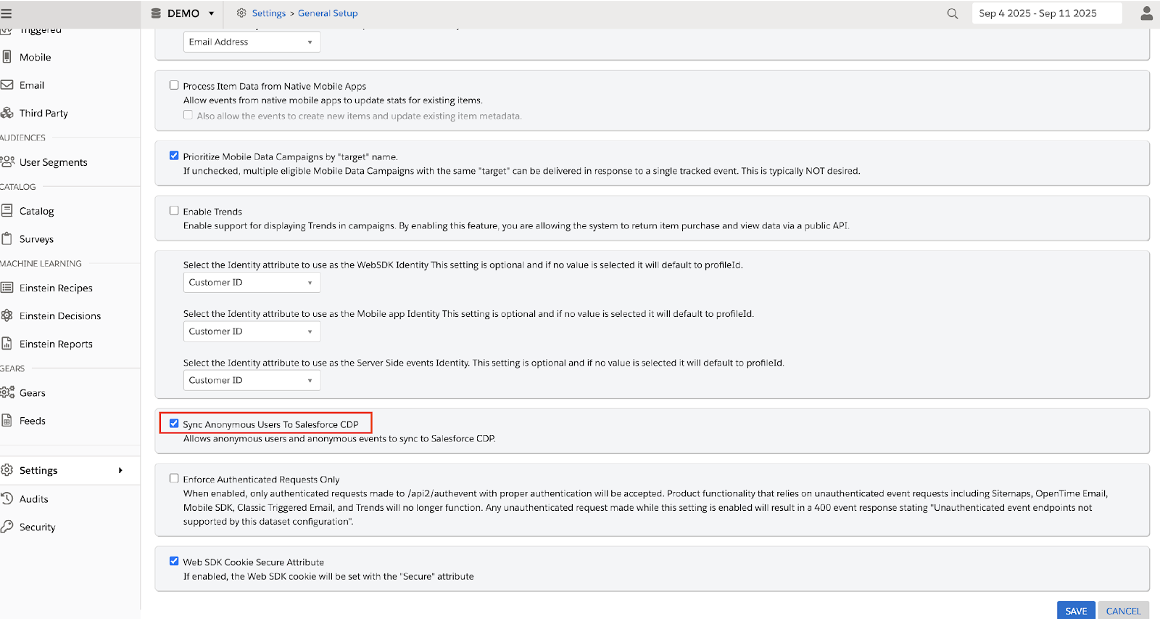
匿名データを連携する場合は、Personalizationの管理画面から「Sync Anonymous Users To Salesforce CDP」にチェックを付けることで、匿名データも含めてData Cloudに連携することが可能となります。(※Data Cloudはレコード量や処理量による消費型ライセンスのため、匿名データを連携する場合は慎重に検討してください。)
【匿名データを連携する】
1-1. Marketing Cloudにログインします。
1-2. Personalizationの管理画面からSettings > General Setup に遷移します。
1-3.「Sync Anonymous Users To Salesforce CDP」にチェックします。
②Data CloudとPersonalizationを接続する
Data Cloud環境とPersonalization環境を接続します。
Personalizationと接続する際は、Personalizationの管理者権限を持つユーザが必要になりますので、Marketing Cloudでユーザを新規作成します。
【Marketing Cloudに接続用ユーザを作成する】
2-1. Marketing Cloudにログインします。
2-2.セットアップ > ユーザー > ユーザーに遷移します。
2-3. 「作成」から新しいユーザを作成する
2-4. 作成したユーザーに対して、以下のロール/権限を付与する
ロール:Marketing Cloud 管理者、管理者
権限:Personalizationのアクセス、管理者を「許可」
<ロール設定>
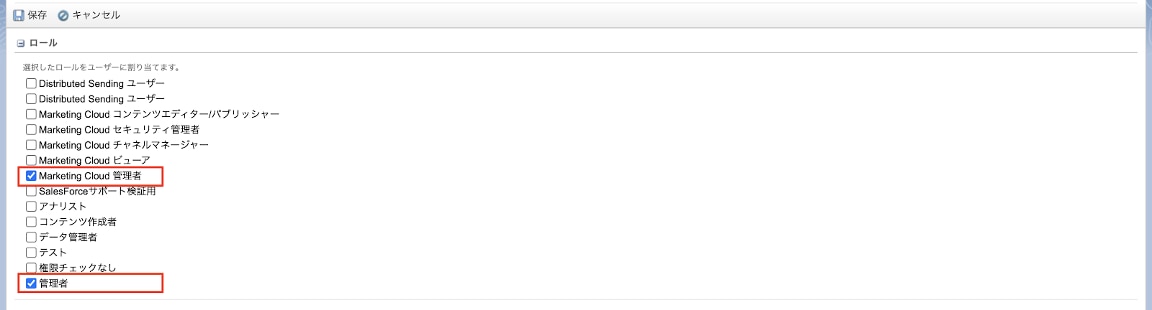
<権限設定>

接続用ユーザの作成が完了したらData CloudとPersonalizationを接続します。
Data Cloudの管理画面から接続設定をしていきます。
【Data CloudとPersonalizationを接続する】
2-5. Data Cloudにログインします。
2-6. 画面右上の歯車からData Cloud設定>マーケティング>パーソナライズに遷移します。
2-7.「新規」または「接続」をクリックすると、Marketing Cloudのログイン画面が表示されるので、作成した接続用ユーザでログインします。
2-8. 接続が成功すると一覧に接続したPersonalization環境が追加されます。

次に、Personalizationのどのデータセットと接続するかを設定する必要があります。(※データセットとは、Personalization内で分離された環境のことです。よくある使用例としては、本番環境と開発環境をわける場合などに使用します)
追加されたPersonalization環境の右側にある「▼」メニューから「編集」をクリックして接続するデータセットを決定します。
ここが躓きポイントです。なぜか「編集」がメニューに出てきません。(2025/9/11時点)

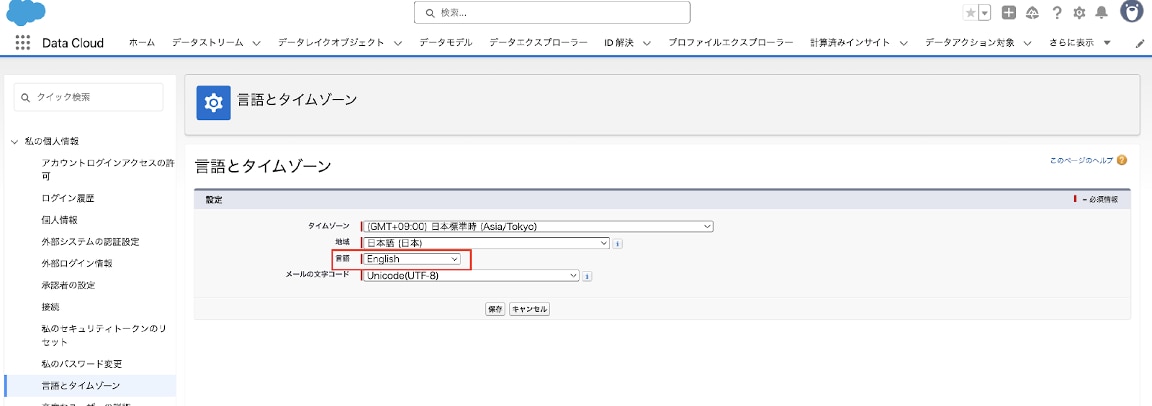
この「編集」メニューはユーザーの言語設定を「日本語」にしていると表示されない仕様のようで、言語設定を「英語」に切り替えることで表示されます。

それでは、言語設定を英語に切り替える所から実施していきましょう。
【接続するデータセットを設定する】
2-9. 画面右上の自身のアイコンを選択して「設定」をクリックします。私の個人情報>言語とタイムゾーンから言語を「English」に選択して保存します。
2-10. 画面右上の歯車からData Cloud Setup>Marketing> Personalizationに遷移します。
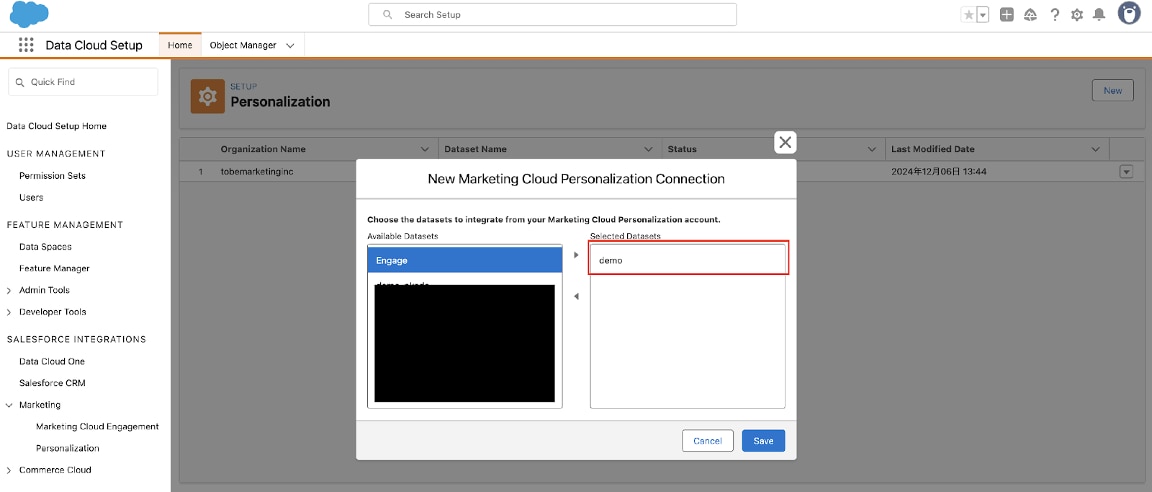
2-11. 追加したPersonalization環境の右側にある「▼」メニューから「Edit」クリックします。Personalizationのデータセットの一覧が表示されるため、接続するデータセットをSelected Datasetsに追加して「Save」をクリックします。
これにてData Cloud環境とPersonalization環境の接続は完了です。
以降の作業は言語設定を「日本語」に戻しても設定できますので、必要な方は戻しておきましょう。
③Personalizationデータストリームを作成する
Data Cloud環境とPersonalization環境の接続設定が完了したので、実際にデータを取り込める状態になりました。PersonalizationのデータをData Cloudに取り込みましょう。
【Personalizationデータストリームを作成する】
3-1. Data Cloudにログインします。
3-2. データストリームの管理画面から「新規」をクリックし、接続済みソースから「Marketing Cloud Personalization」を選択して「次へ」をクリックします。
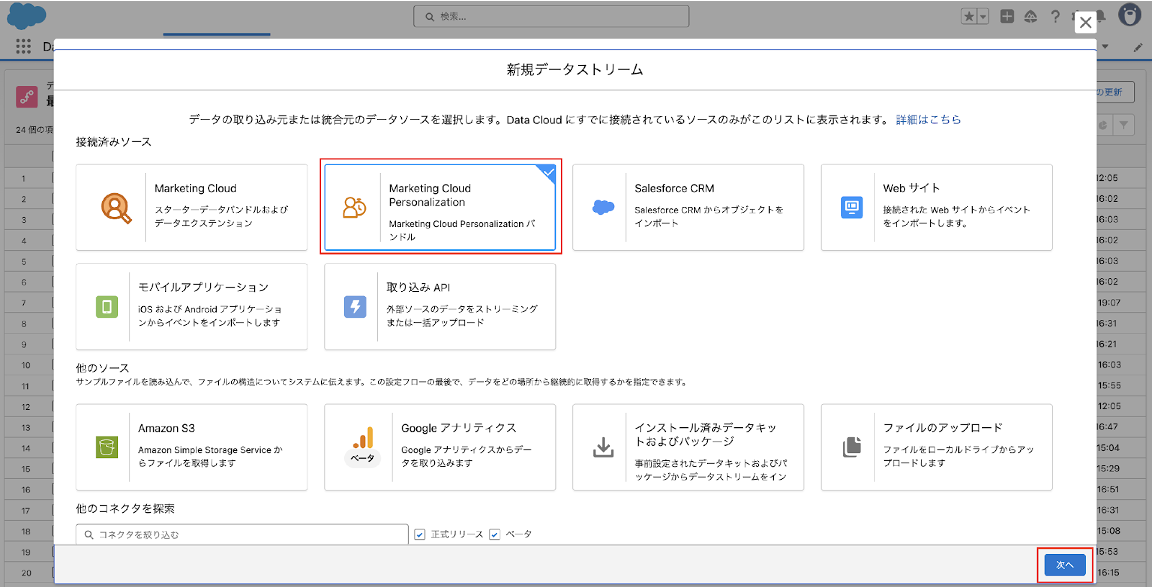
3-3. 「Marketing Cloud Personalization データセット」に取り込み対象のデータセットを選択、「選択 ID サフィックス」に任意の文字列を入力して「次へ」をクリックします。
(※「選択 ID サフィックス」は、作成されるデータストリーム名に付与されるサフィックスとなります。例えば、本番と開発の2つのデータセットから取り込む場合には、prod、devのようにそれぞれわかりやすいサフィックスを設定することで、どのデータセットから連携したデータか一目でわかりやすくなります。)
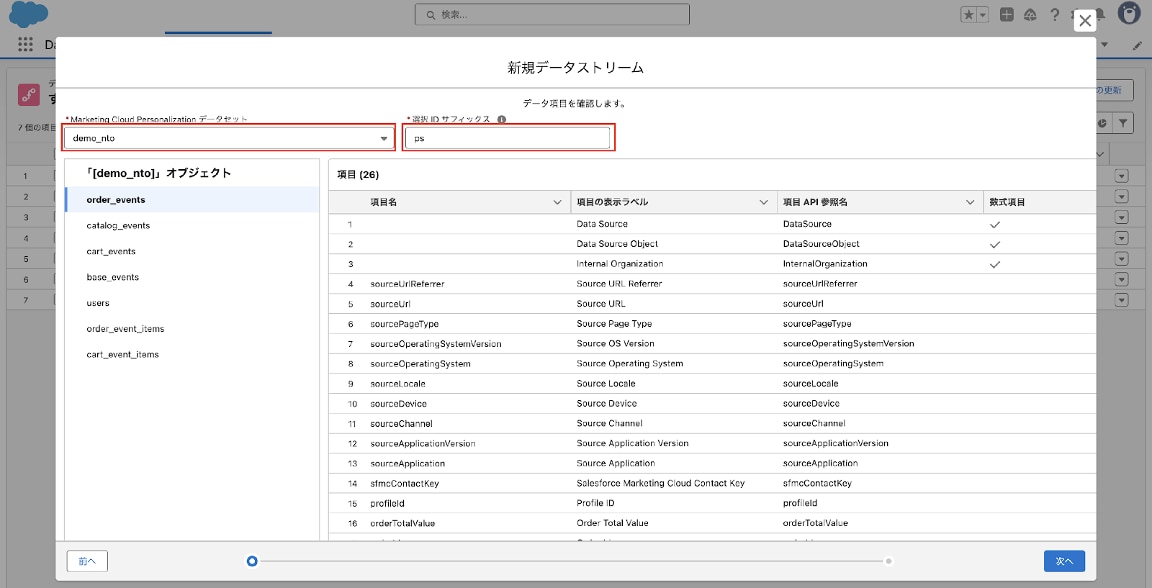
3-4. 作成されるデータストリームオブジェクトの一覧を確認し、「リリース」をクリックします。
3-5. データストリームの一覧にPersonalizationから連携されるデータストリームが7つ作成されます。
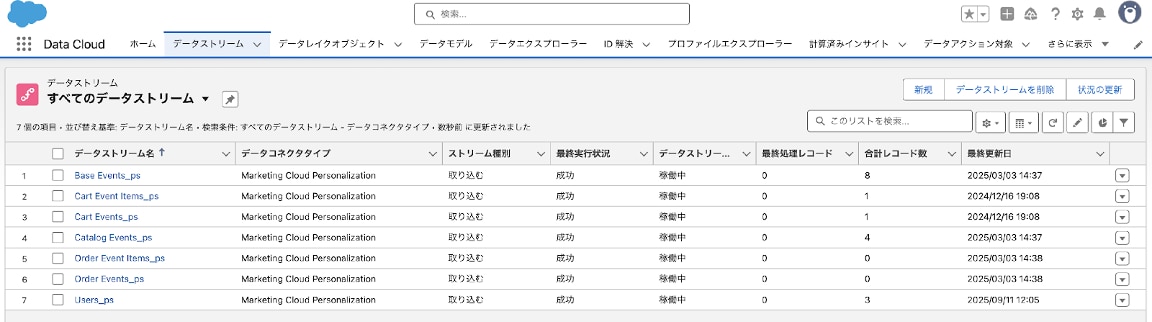
以上でPersonalizationのデータがData Cloudに連携されました。
覚えておくべきポイントをいくつかご紹介
ポイント①:連携頻度
Personalizationから連携されるデータストリームは、リアルタイム連携ではなく、1時間に1回の頻度で連携されます。
ポイント②:過去データの取り込み
Data Cloudに連携されるデータは、データストリームを作成した以降にPersonalizationで取得されたデータに限ります。Personalizationで過去に取得しているデータを遡って連携することはできません。
顧客情報に関しても同様ですが、顧客情報に関してはPersonalizationで更新されれば連携対象となります。
次に、連携された7つのデータストリームの中身について解説していきます。
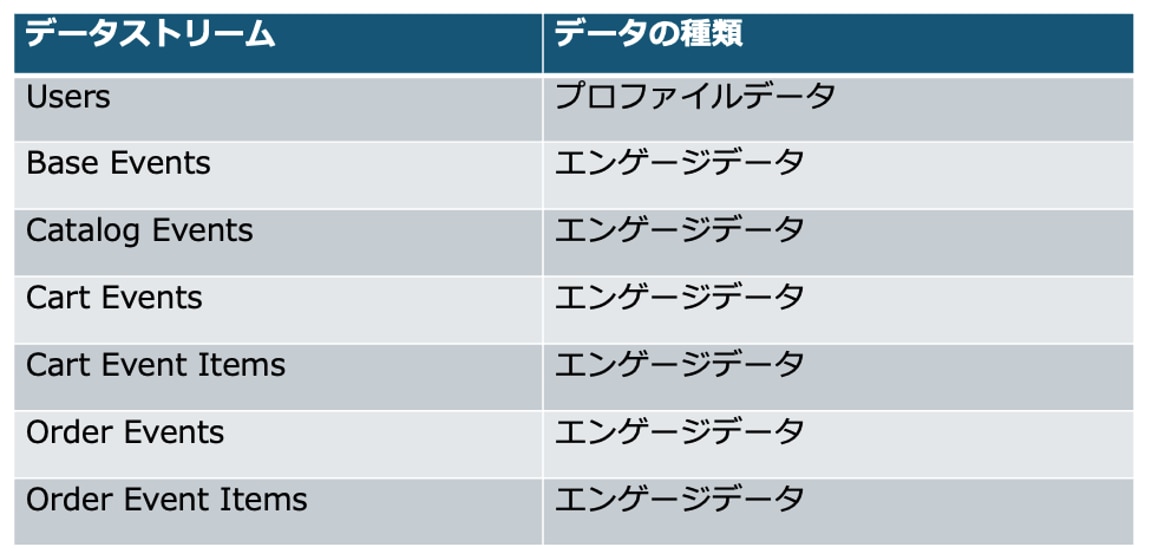
7つのデータストリームは大きく2種類に分かれており、プロファイルデータとエンゲージデータとなります。プロファイルデータはその名の通り顧客データで、エンゲージデータは行動データという種類を表しています。
下記の通り、「Users」のみプロファイルデータで、それ以外はすべてエンゲージデータであることがわかります。
データの種類がわかったところで、次に、各データストリームにどのようなデータが格納されるか解説していきます。
まずはプロファイルデータである「Users」データストリームです。
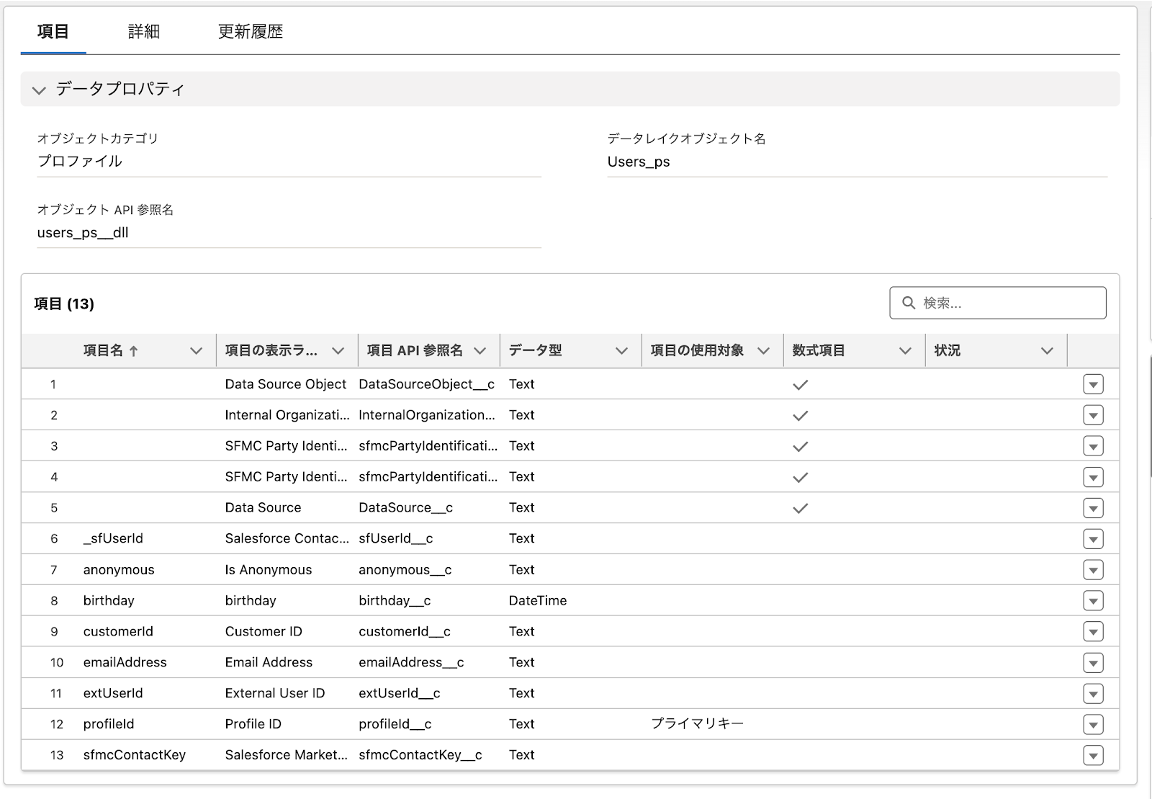
・Users
PersonalizationのUsersマスタのデータが格納されます。
Usersマスタで定義している属性項目(カスタムで作成した属性も含む)、ID属性項目(ログインIDなどの顧客識別ID)、匿名フラグが項目として連携されます。
レコードのプライマリーキーは「Profile ID」という項目で、これはPersonalizationの「User ID」項目に該当します。
※データ連携後にPersonalization 側でUsersの属性項目を追加・削除・変更しても、その変更はData Cloud側に反映されません。事前にPersonalization側の定義を作成した上で作業を実施することをおすすめします。
Data Cloudに連携される項目
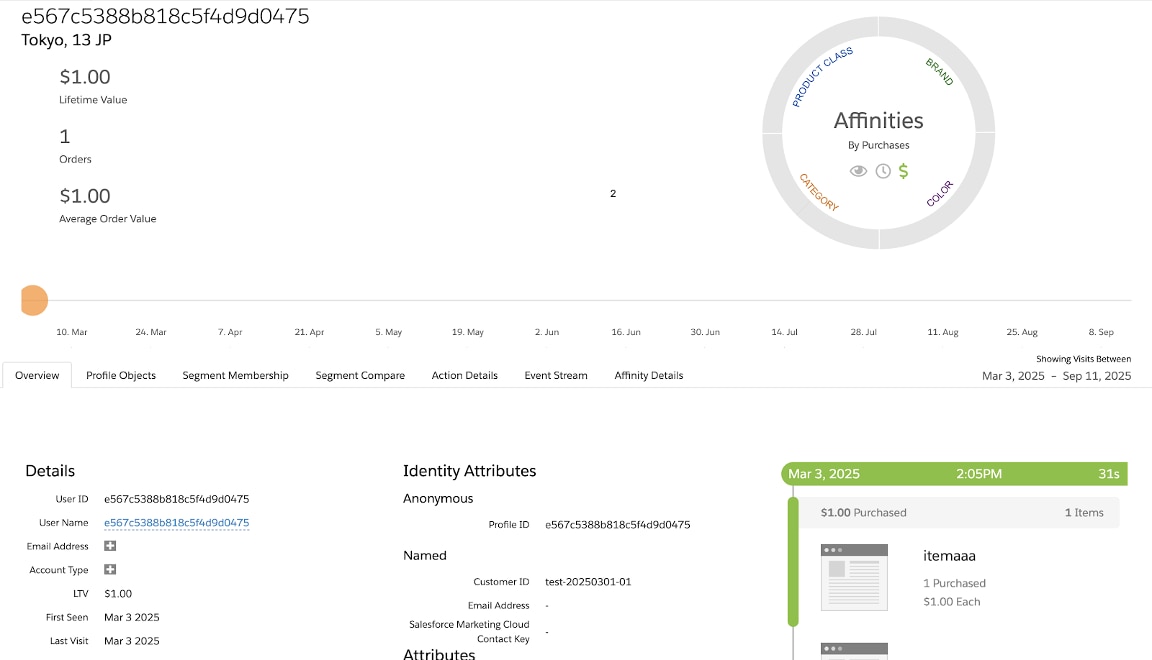
Data Cloudに連携されるレコード

Personalizationのレコード
次に、エンゲージデータになりますが、より理解を深めるためにPersonalizationで取得するイベントデータについて簡単に説明します。
Personalizationで取得するイベントデータは、カタログに関連するイベント(ItemAction)とカタログに関連しないイベント(Action)の大きく2つに分かれます。
カタログとは、Webやアプリで販売している商品など、顧客に提供する商品やコンテンツを保存するマスタデータになります。(本記事では、カタログ = 商品データとして説明していきます。)
つまり、商品に関連するイベントと商品に関連しないイベントの大きく2つに分かれるということです。では、それぞれのイベントで取得されるイベントの例を見てみましょう。

大きく2つの種類のイベントがあることがわかったと思います。
上記を踏まえて、エンゲージデータとして連携されるデータストリームについて解説していきます。
・Base Events
カタログに関連しないイベントデータが格納されます。
例)TOPページを閲覧した、ログインした
・Catalog Events
カート/購入以外のカタログに関連するイベントデータが格納されます。
例)商品を閲覧した
・Cart Events
カート操作に関連するイベントデータが格納されます。
例)カートに追加した、カートから削除した
※カート操作のイベントだけを格納するため、カタログ単位(どんな商品をカート追加したか?)までは保持しません。カタログ単位のデータは後述するCart Event Itemsにて保持します。
・Cart Event Items
Cart Eventsのカート操作イベントに紐づくカタログ単位のイベントデータが格納されます。
例)商品ID:Item1を数量1追加した、商品ID:Item2を削除した
※Cart Eventsではカート操作のイベントの種類、そのイベントで発生したカタログ単位のデータがCart Event Itemsと覚えておきましょう。
・Order Events
購入操作に関連するイベントデータが格納されます。
例)商品を購入した
※購入操作のイベントだけを格納するため、カタログ単位(どんな商品を購入したか)までは保持しません。カタログ単位のデータは後述するOrder Event Itemsにて保持します。
・Order Event Items
Order Eventsの購入操作イベントに紐づくカタログ単位のイベントデータが格納されます。
例)商品ID:Item1を数量2購入した
※Order Eventsでは購入操作のイベント、そのイベントで発生したカタログ単位のデータがOrder Event Itemsと覚えておきましょう。
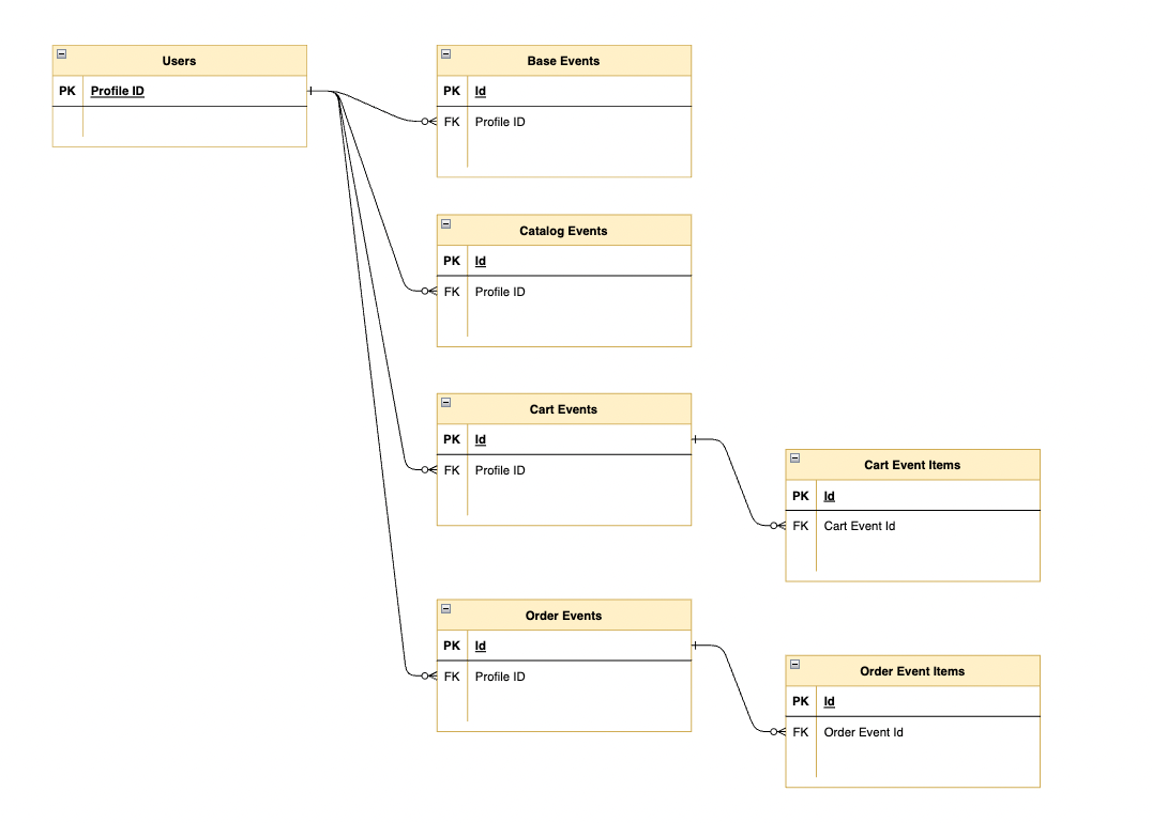
7つのデータストリームの関係を図に示したものがこちらです。
プロファイルデータUsersからすべてのエンゲージデータに紐づけることができます。
④データモデルを設定する
Personalizationから連携されるデータの理解ができたところで、データモデルへマッピング設定をしていきます。
Data Cloudでデータを扱うためには、データモデルオブジェクトに対して連携したデータをマッピングする必要があります。
下記の通り、いくつかのデータストリームは自動的にマッピングまで作成されます。
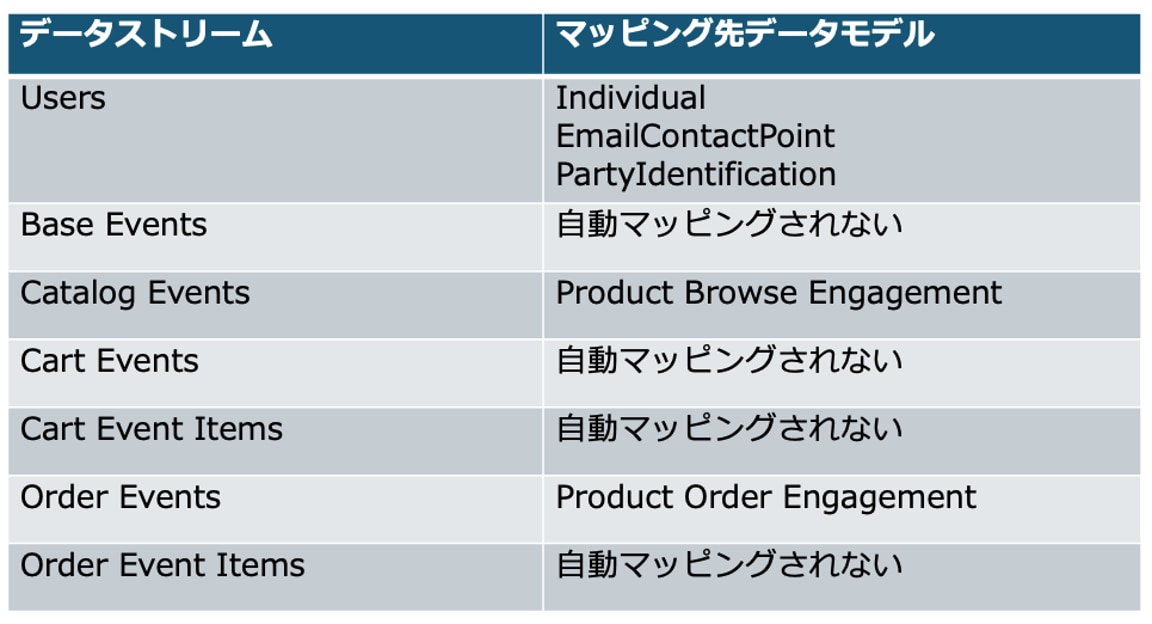 自動マッピングされない「Base Events」「Cart Events」「Cart Event Items」「Order Event Items」に関しては、手動でデータモデルへのマッピングを実施する必要があります。
自動マッピングされない「Base Events」「Cart Events」「Cart Event Items」「Order Event Items」に関しては、手動でデータモデルへのマッピングを実施する必要があります。
手動マッピングが必要なデータストリームに関しては、下記の通り標準データモデルにマッピングすることが推奨されています。
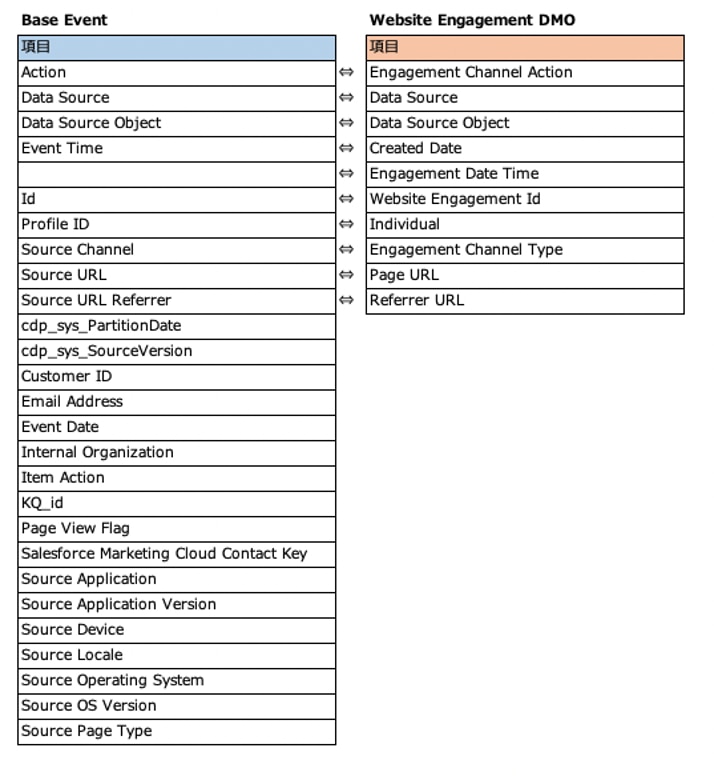
・Base Events → Website Engagement DMO
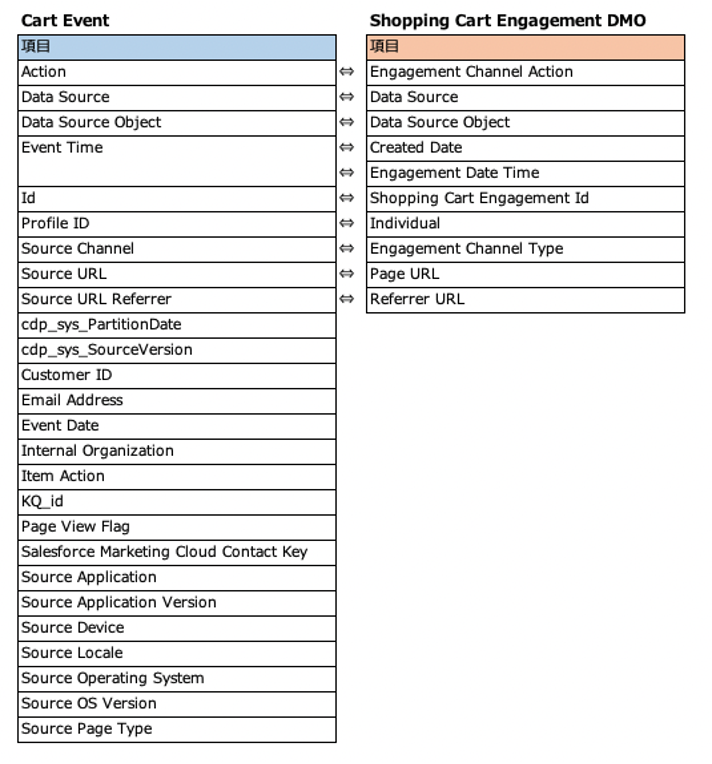
・Cart Events → Shopping Cart Engagement DMO
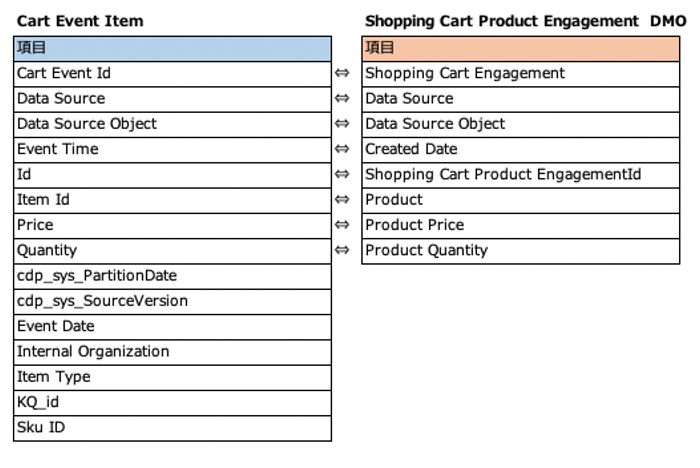
・Cart Event Items → Shopping Cart Product Engagement DMO
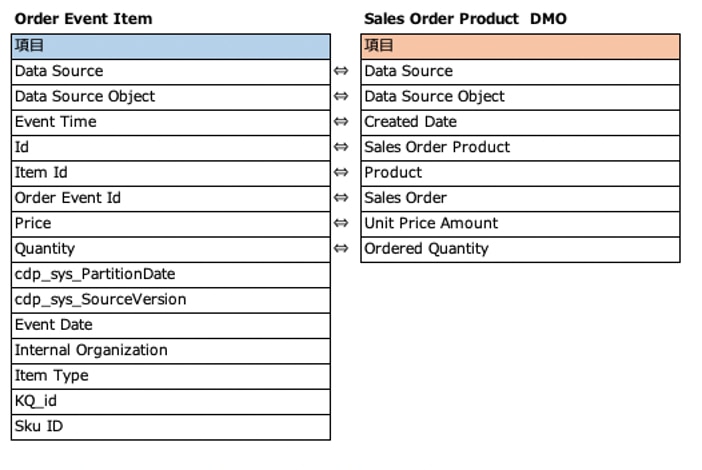
・Order Event Items → Sales Order Product DMO
それでは、マッピングの設定をしていきましょう。
【データモデルマッピングを作成する】
※本手順では「Base Events」を元に解説しますが、残りの「Cart Events」「Cart Event Items」「Order Event Items」も同様の手順となります。(マッピング先のデータモデルは異なります。)
4-1. Data Cloudにログインします。
4-2. データストリームの一覧の中から「Base Events_サフィックス」をクリックします。
4-3. 画面右に表示されるデータマッピングセクションの「開始」をクリックします。
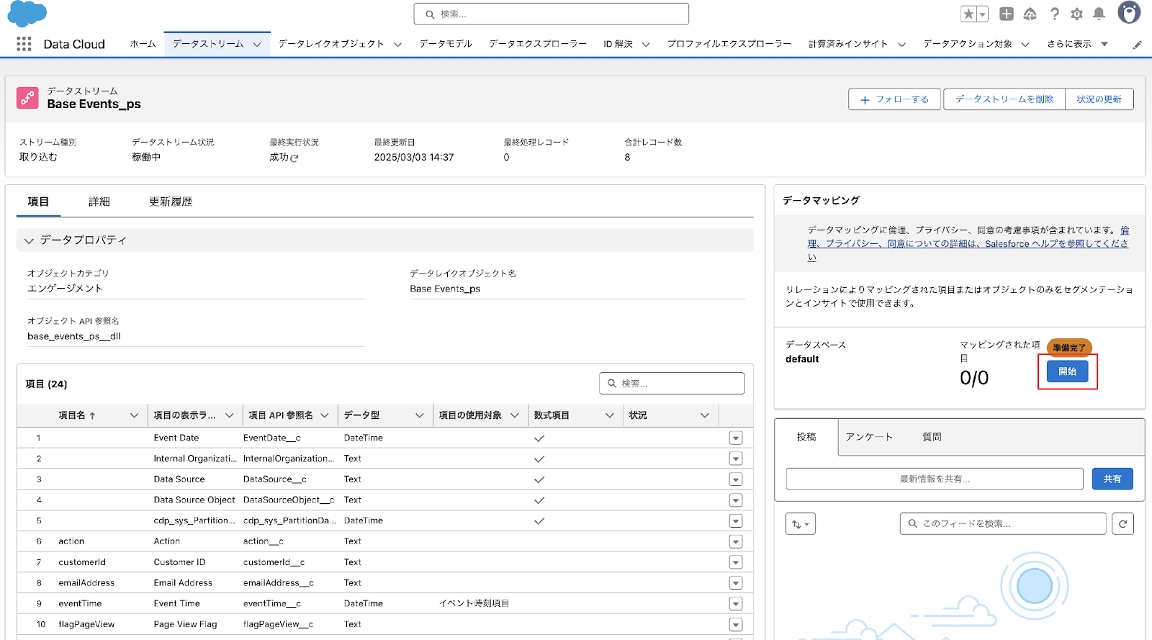
4-4. 画面右のデータモデルエンティティから「オブジェクトの選択」をクリックします。
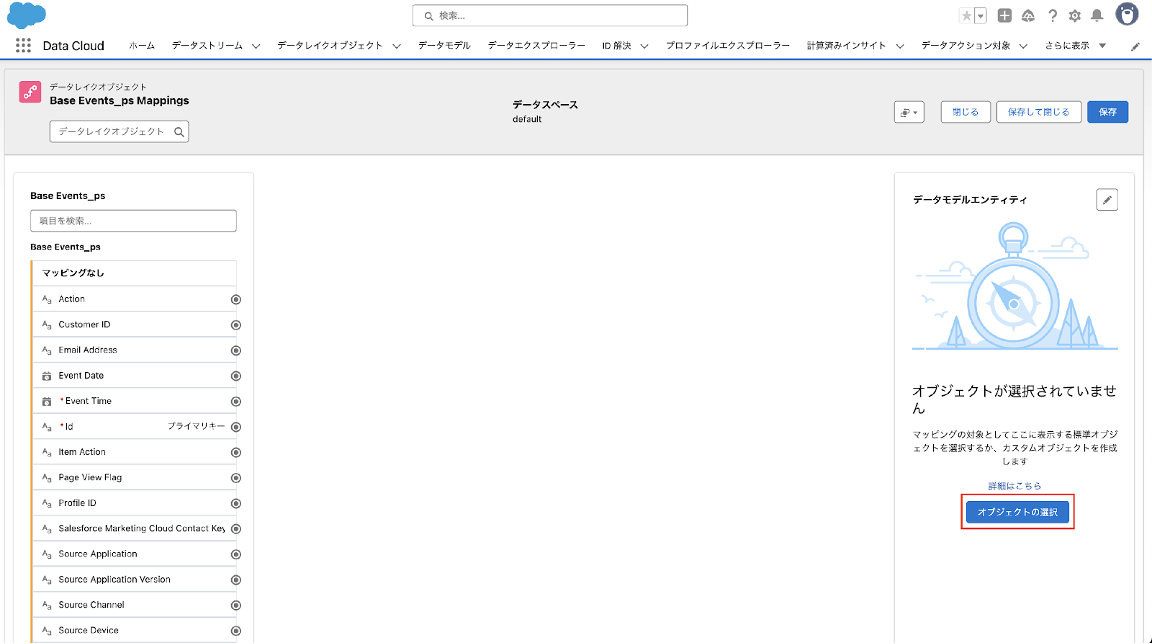
4-5. 推奨されるデータモデルを選択して、「完了」をクリックします。(※Base Eventsの場合、Website Engagement)
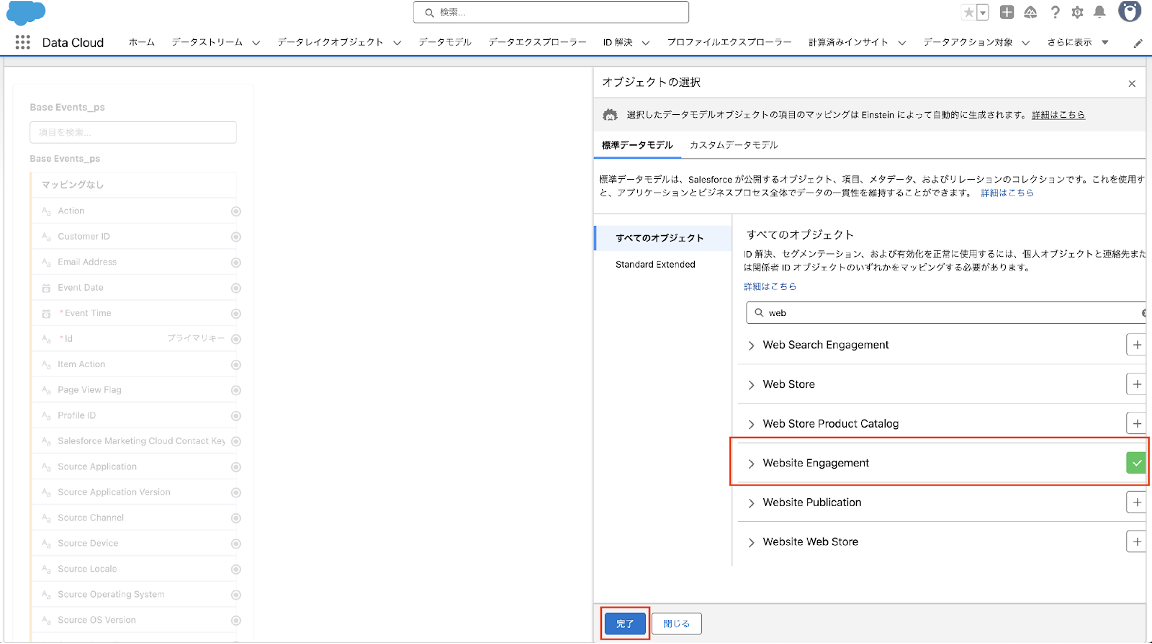
4-6. 項目のマッピングを実施して、画面右上の「保存」をクリックします。
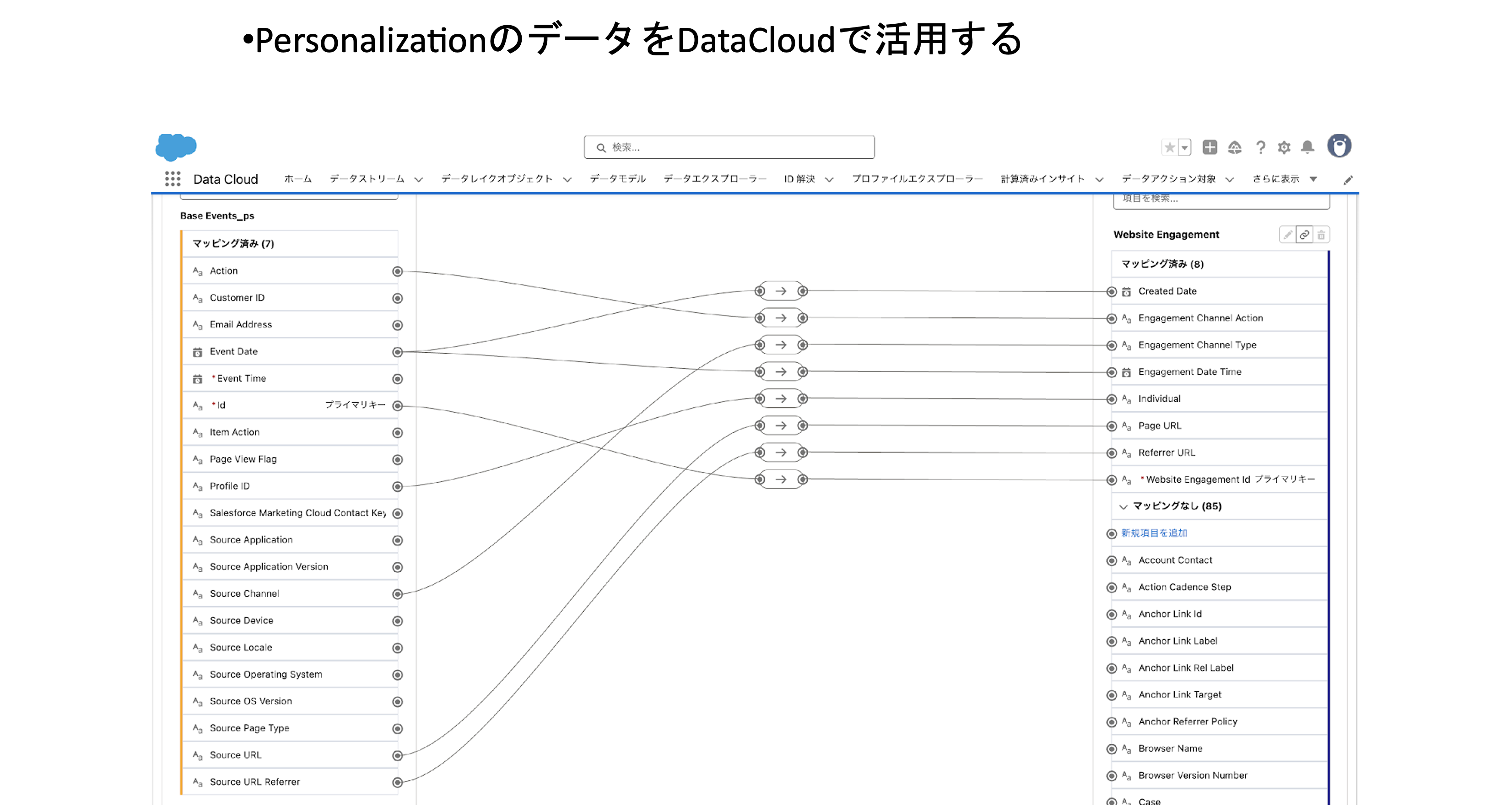
項目レベルのマッピングに関しては、どの項目とどの項目をマッピングするべき。といった推奨設定はありません。
標準データモデルのリファレンスを確認の上、自身で判断して適切な項目にマッピングする必要があります。
https://developer.salesforce.com/docs/data/data-cloud-dmo-mapping/guide/c360dm-website-engagement-dmo.html
参考までに弊社は、以下の項目マッピングで設定することが多いです。
・Base Event
・Cart Event
・Cart Event Item
・Order Event Item
以上で、データモデルマッピングの設定は完了です。
次に、データモデル間のリレーション設定が必要になります。
「Product Order Engagement」は、受注単位のデータであるOrder Eventsデータストリーム、「Sales Order Product」は、受注商品単位のデータであるOrder Event Itemsデータストリームをマッピングするため、「Product Order Engagement」と「Sales Order Product」でリレーションが必要ですが、デフォルトでは設定がされていません。
弊社の項目マッピングの設定の場合、
Product Order Engagement. Product Order Engagement Id = Sales Order Product. Sales Order(1:N)でリレーション設定が可能となりますので、手順を解説していきます。
※弊社の例とは別の項目マッピングをしている場合、リレーション設定する項目が異なる可能性がありますので注意してください。
【データモデル間のリレーションを作成する】
4-7. データモデルの一覧画面に遷移します。
4-8. データモデルの一覧から「Sales Order Product」をクリックします。
4-9. リレーションタブに遷移し「編集」をクリックします。
4-10. 以下のリレーションを設定し、「保存」をクリックします。
オブジェクト:Sales Order Product
項目:Sales Order
多重度:N 対 1
関連オブジェクト:Product Order Engagement
関連項目:Product Order Engagement Id
以上で、データモデルの設定は完了となります。
データモデルマッピングに関しては、マッピング先のデータモデルは自動的にされるものとされないものがある点、手動の場合も推奨されるデータモデルはあるが、項目レベルのマッピングに関しては要件やデータ内容により自身で判断していく必要がある点に注意点が必要です。
参考までに、データエクスプローラーやクエリエディターといった機能を用いて、データストリーム上に連携される実際のレコードの中身を確認することもできますので、実データを参照しながらマッピングを進めていくことも検討してください。
⑤ID解決を設定する
これまでの手順で、Personalizationとの接続/データの取り込み/データモデルの設定まで完了しました。最後にID解決の設定をしていきます。
下記の例のように、外部データソースとしてAWS S3から顧客データを連携していると仮定した場合、Personalizationの顧客データとは別レコードとなります。そのため、AWS S3の顧客データとPersonalizationの顧客データ/エンゲージデータの紐付きもないため、この時点ではPersonalizationのデータを活用することができません。
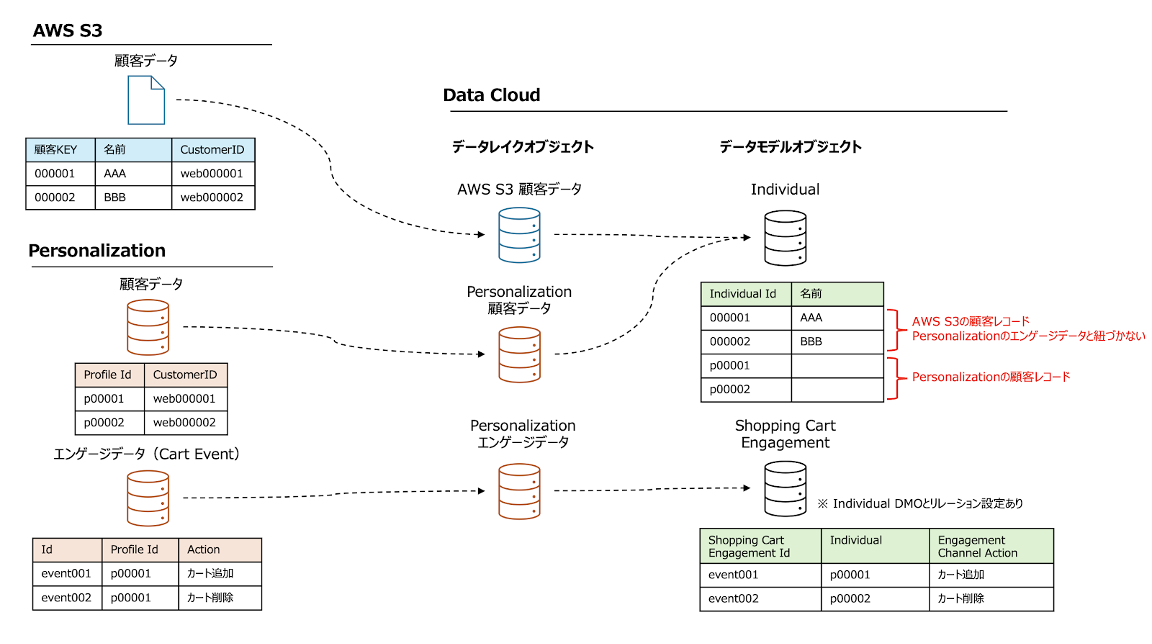
これを解決するには、AWS S3の顧客データとPersonalizationの顧客データをID解決で顧客統合を行い、統合プロファイルを作成する必要があります。
本記事では、データモデル「Party Identification」と呼ばれる顧客IDや免許証番号など人の識別番号を管理するためのデータモデルを使用してID解決を作成する手順を解説していきます。
※前提として、AWS S3の顧客データとPersonalizationの顧客データに顧客を識別できる共通のID項目を保持している必要があります。
※ID解決のルールに関してはデータ状態や保持する項目により設定内容が異なるため、要件に合わせて設定してください。
【データモデル「Party Identification」へのマッピングを設定する】
5-1. Data Cloudにログインします。
5-2. データストリームの一覧の中から「Users_サフィックス」をクリックします。
5-3. 画面右に表示されるデータマッピングセクションの「確認」をクリックします。
5-4. データストリーム「Users_サフィックス」項目「Salesforce Marketing Cloud Contact Key」 = データモデル「Party Identification」項目「Identification Number」のマッピング設定を削除します。
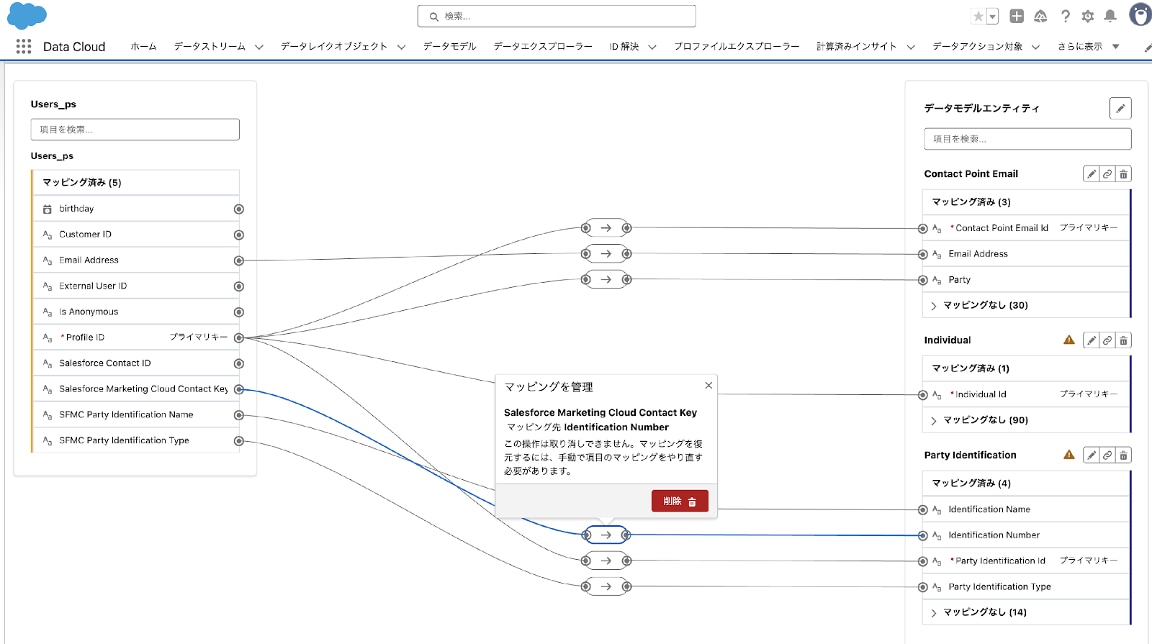
5-5. ID解決のルールに使用する項目(今回は「Customer ID」)をデータモデル「Party Identification」項目「Identification Number」にマッピングします。
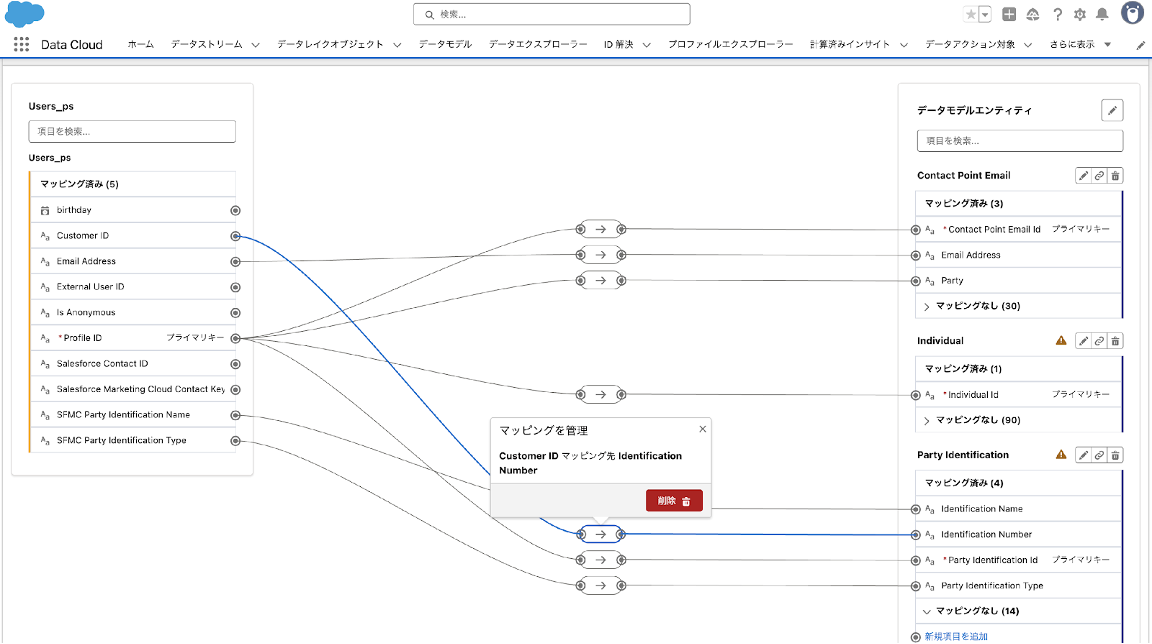
5-6. AWS S3の顧客データのデータストリームに2つの数式項目を新規作成します。
・SFMC Party Identification Type
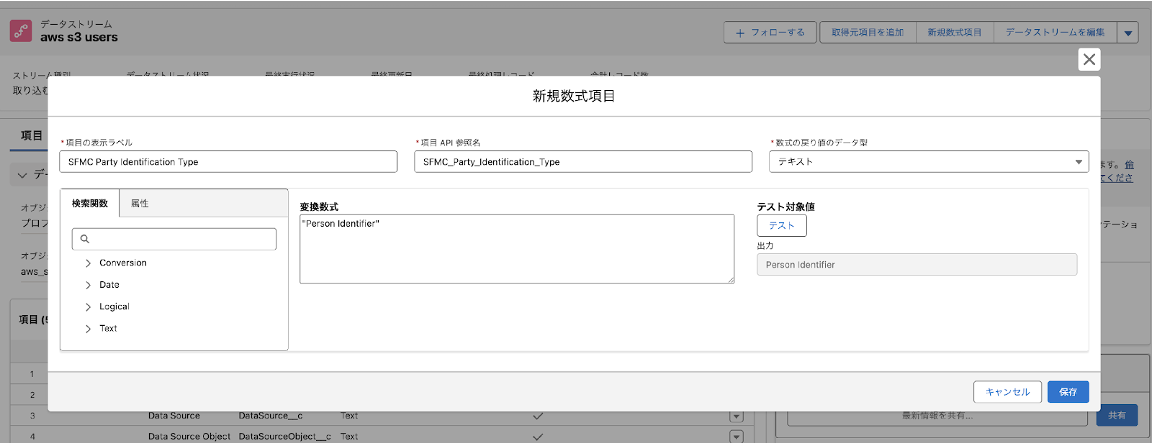
・SFMC Party Identification Name
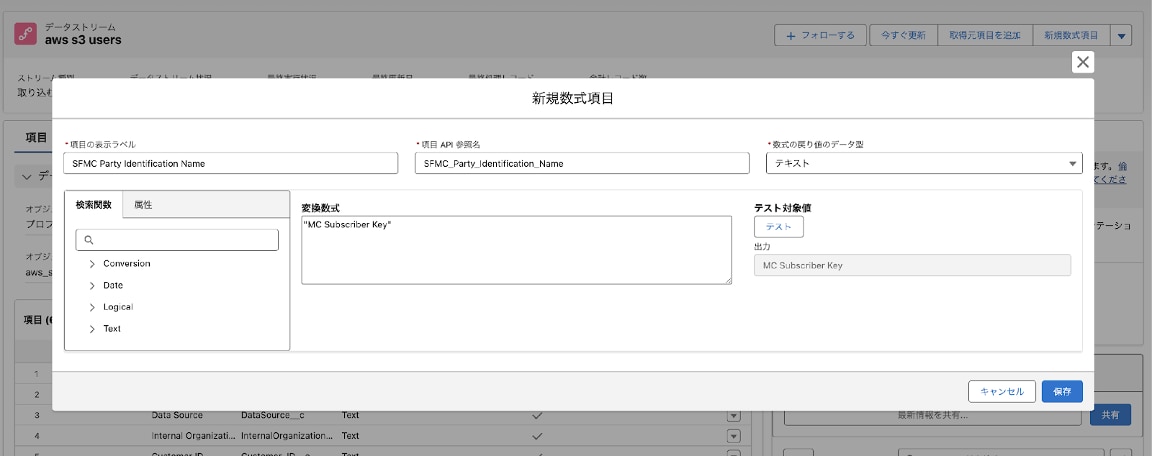
この2つの数式はデータモデル「Party Identification」の項目「Identification Name」と「Party Identification Type」にマッピングするための項目となります。
識別子の名前と種類を表す項目となり、データモデル「Party Identification」でID解決をする場合に必須となる項目です。
Personalizationから連携される顧客データ「Users_サフィックス」は、上記項目が自動的にSFMC Party Identification Name = “MC Subscriber Key”、 SFMC Party Identification Type = “Person Identifier”として連携され、データモデルに自動マッピングされるため、AWS S3側の顧客データも同様の値の名前、種類の項目を用意しておきます。
※後から数式項目を追加した場合、データのフルリフレッシュをしないと過去のレコードに反映されないため、数式設定後に再度全件連携を行うorデータストリームの初期作成の時点で作成するようにしてください。
5-7. AWS S3の顧客データのデータストリームをデータモデル「Party Identification」にマッピングし「保存」をクリックします。
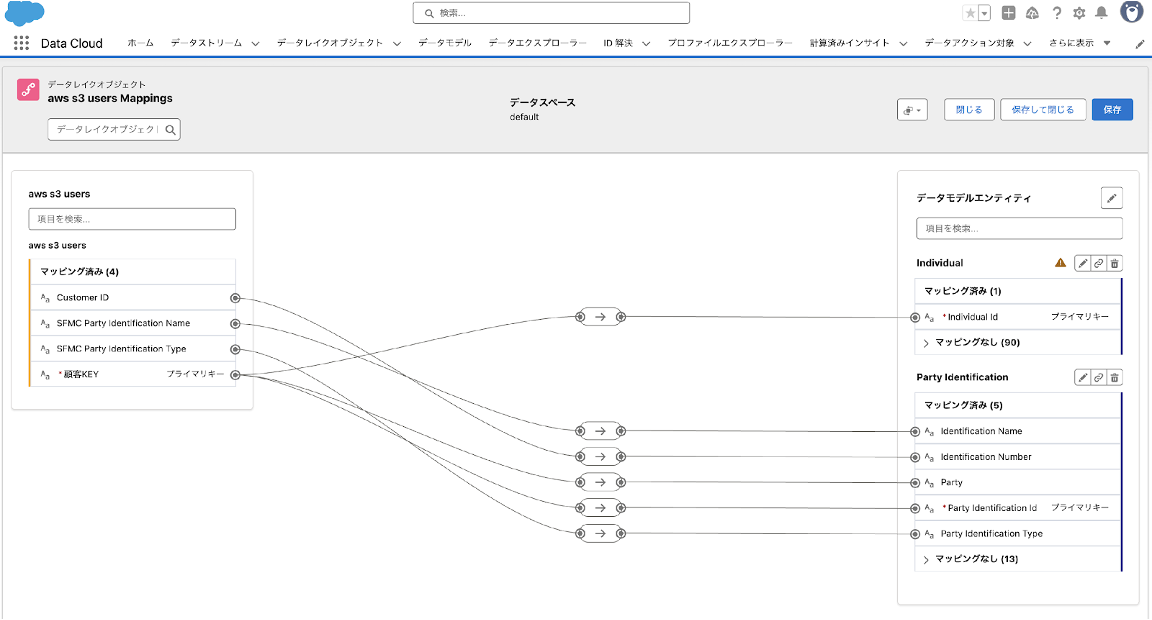
Customer ID、SFMC Party Identification Name、SFMC Party Identification Typeをマッピングします。その他のマッピングは必要に応じて設定してください。
・Customer ID → Identification Number
・SFMC Party Identification Name → Identification Name
・SFMC Party Identification Type → Party Identification Type
以上で、ID解決を作成するための前準備は完了です。続いてID解決を作成していきましょう。
【ID解決を作成する】
5-8. ID解決の一覧から「新規」をクリックします。(※既存のID解決を編集する場合は、既存のID解決をクリック)
5-9. プライマリデータオブジェクトに「Individual」、ルールセットID、ルールセット名を入力して「保存」をクリックします。
5-10. 一致ルールの設定から「カスタムルール」を指定します。
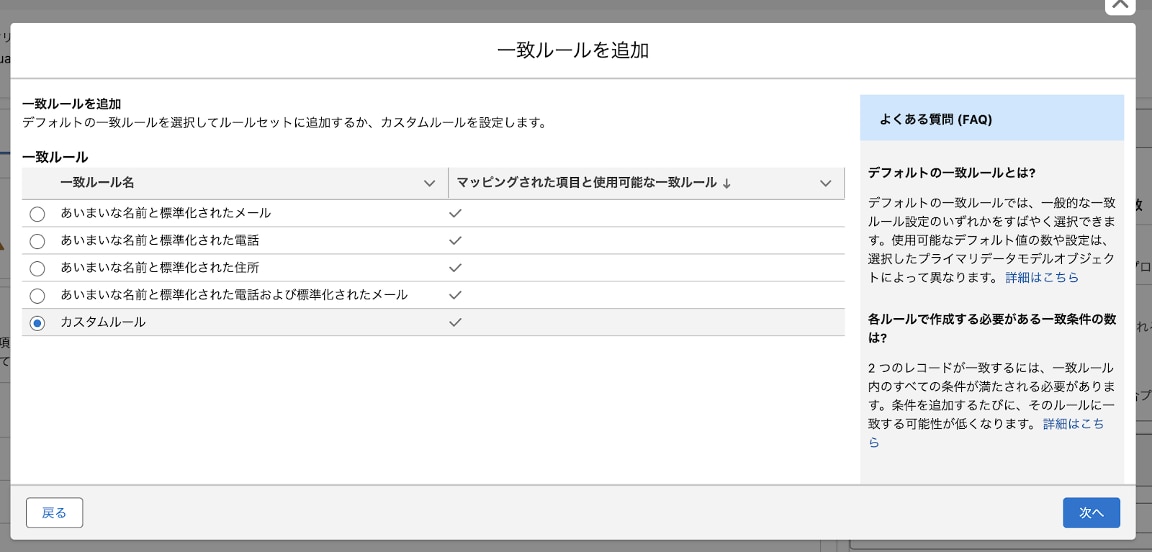
5-11. データモデルオブジェクトに「Party Identification」、項目に「Identification Number」、照合方法に「完全」を選択し、「設定」をクリックします。
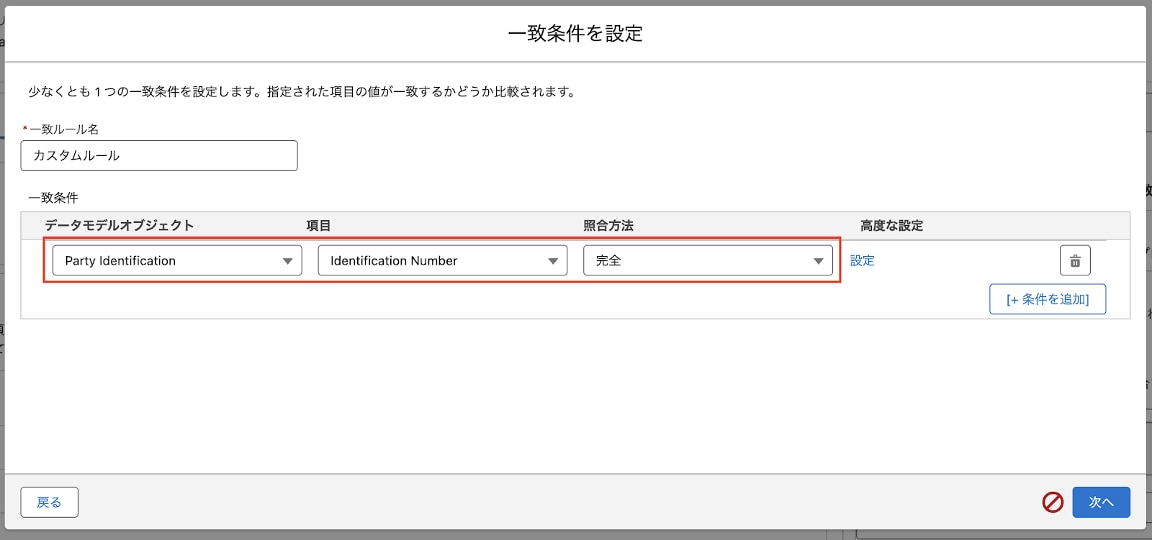
5-12. 関係者ID種別に「Person Identifier」、関係者ID名に「MC Subscriber Key」を入力し、「基本設定へ戻る」をクリックします。
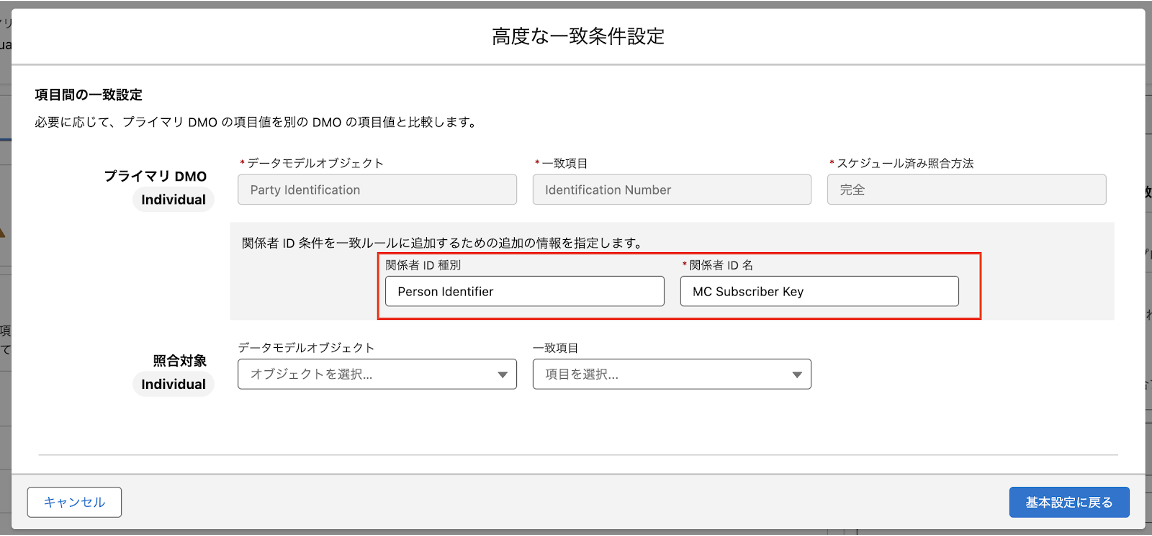
5-13. 「次へ」をクリック、「保存」をクリックして一致ルールを保存します。
以上で、ID解決の作成は完了です。
ID解決を実行することで、AWS S3の顧客データとPersonalizationの顧客データがCustomer IDに基づいて、統合プロファイルが作成されます。
マーケティング施策やデータ分析等で、統合プロファイルをベースに実施することで、Personalizationのデータも含めて活用できる状態となりました。
実際のデータをデータエクスプローラやクエリエディタで確認いただくとイメージが付きやすいと思いますが、どのようなデータ状態になったかを表したものが下記の図となります。
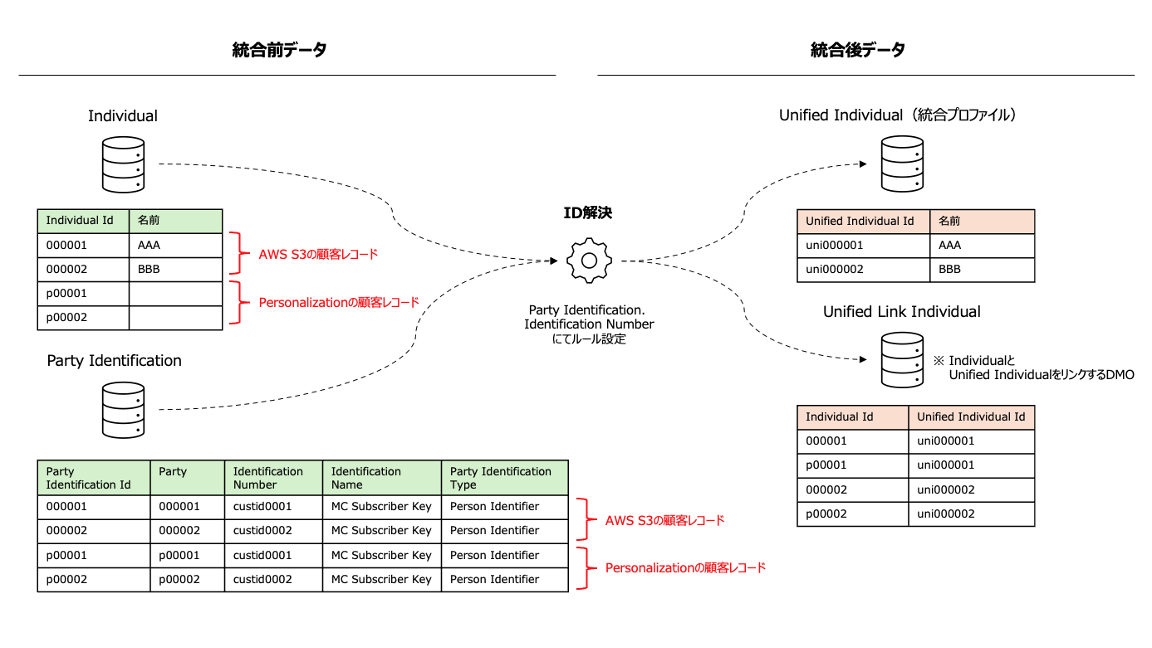
まとめ
いかがでしたでしょうか。
Personalizationで収集したデータをCDPであるData Cloudに取り込み、顧客理解を深めることで、データ活用の幅が大きく広がります。
ぜひ、今回の内容を参考に、Data CloudとPersonalizationの連携によるデータ活用に挑戦してみてください。
✔Data CloudとMarketing Cloud or Account Engagementを連携させるとどのような効果があるのか知りたい方
✔Marketing Cloud or Account Engagement外にあるデータソースを掛け合わせた条件でリストを作成したい
✔組織が事業部ことに複数ありデータの統合をしたい方
上記のようなお悩みをお持ちの方は、ぜひ!弊社サービスをご活用ください!

\お困り事はお気軽にご相談ください/
Data Cloud の基本と活用法!
MA課題をデータで解決する
方法とは?
本ホワイトペーパーでは、Data Cloudの基礎を知りたい企業様や、データ活用を強化しマーケティング施策の効果を最大化していきたい企業様向けに、Data Cloudの導入・運用を成功させるためのポイントをご紹介いたします。
\詳細はこちらをクリック/









